API 설계
[입소대기신청시스템]
[POST] /enterwait/request : 8. 입소대기 신청
[GET] /enterwait/inquiry : 9. 입소 대기 신청 조회
[POST] /enterwait/inquiry : 10. 입소 대기 신청 수정/삭제
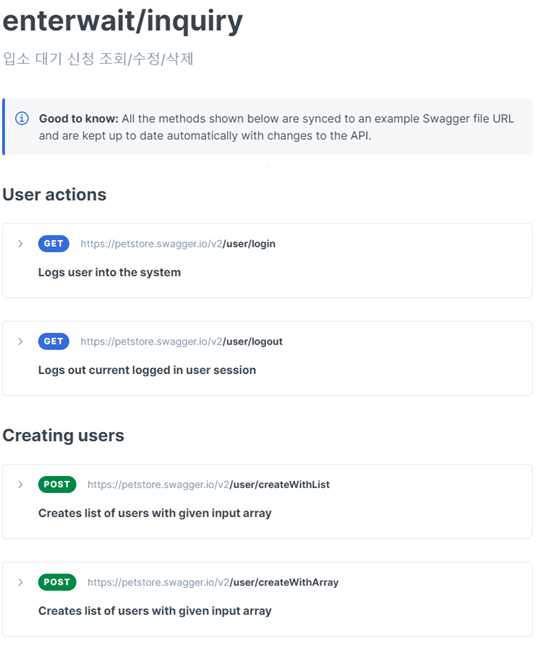
[아동관리시스템]
[POST] /enterwait : 3. 신청 아동 입소 등록 (알림 전송 포함)
[POST] /enterwait/:id : 4. 신청 아동 수정 (보류/취소)
[GET] /child : 5. 입소 등록 조회
여기에서 Child_id 조회 했을때 3개의 Query가 조회 됩니다.
1. Status "Waiting"
2. Status "Success"
3. Status "Failed"
또한 내용이 수정되어도 PUT Method을 사용하지 않고 POST Method으로 사용했습니다. 실제 업종에서 POST를 주로 사용하고 POST 방식으로 내용 덮어쓰는 식으로 사용할 예정입니다. 수정할 경우 수정된 값으로 표시하고 삭제되는 경우 "삭제"된 값은 비활성화 되어 확인 할 수 없게 됩니다. 삭제된 데이터는 완전이 삭제되지 않고 기록 위해 데이터베이스에 남습니다. 계정이 비활성화 되는 것과 비슷합니다.
일부 용어 정리하겠습니다.
'입소대기신청시스템' : 학부모가 아동 등록 및 입소대기 신청을 하는 시스템
'아동관리시스템' : 어린이집에서 입소대기 신청을 확인하고 아동을 등록하는 시스템
'어린이집관리시스템' : 어린이집 정보를 관리하는 시스템
1차 아키텍처 (큰그림)

팀원 코멘트
현 상황에서 아키텍처를 설계하다보니 어느 문제점에 부딪혔습니다. 입소대기 신청 할 때 어린이집 + 아동 정보를 담아 SNS에 발행, SQS에서 구독한 뒤, 어린이집에서 입소대기 신청 조회를 하면 해당 메시지를 소비할 수 밖에 없는 상황입니다.
하지만 큐에서 메시지를 소비할 경우 해당 메시지는 삭제됩니다. 조회를 1회로 제한할 수 없으니 [아동관리시스템]의 데이터베이스에도 입소대기 신청 정보를 저장할 수 밖에 없습니다.
이때 [입소대기신청시스템]과 [아동관리시스템]이 가진 각 데이터베이스에 동일한 입소대기 신청 정보가 저장되어 있고, 서로 이 중복된 데이터의 일관성을 유지해야하는 것이 설계상 옳은가에 대한 의문이 들었습니다.
입소대기 신청을 할 때 SNS + SQS가 아니라 Redis Stream을 사용한다고 가정하더라도, 다시 신청 -> 보류 -> 신청으로 Active한 상태로 변경 가능한 프로세스가 있으면 Redis Stream 또한 사용이 불가합니다. (Redis Stream은 데이터를 Append 하고 수정은 불가합니다.)
그럼 여기서 또 한 번의 분리를 진행하면 어떻게 될까 고민하게 되었습니다.
입소대기 신청 정보를 관리하는 [입소대기신청관리시스템]을 만듭니다. [입소대기신청시스템]에서 입소대기 신청을 할 때 관리시스템의 데이터베이스에 데이터를 삽입하고, 해당 데이터를 각 시스템에서 조건에 맞게 조회할 수 있는 API를 설계하면 되지 않을까 싶습니다.
[입소대기신청시스템]은 입소대기 신청을 위한 아동 정보만 가지고 있고, [아동관리시스템]은 입소를 완료한 아동 정보만 가지고 있게 됩니다. 이렇게 4개의 마이크로서비스로 분리했을 때 데이터 중복에 대한 문제를 해결하고 일관성을 유지하기 더 쉽지 않을까?라는 생각입니다.
이렇게 되었을 때 각 시스템에서 제공할 API 기능(*표시는 높은 우선순위)입니다.
수정된 아키텍처

수정된 아키텍처에서는 입소대기 신청 시스템에서 동일하게 API Gateway 으로 Lambda 함수 트리거 하는 방식이지만 아동 관리 시스템에 SNS+SQS 추가하여 데이터베이스 정보들이 유지 할 수 있도록 설계 하였습니다.
추가 코멘트 반영하여 3차 아키텍처

4개의 마이크로서비스로 분리으로 작성한 아키텍쳐 다이어그램입니다. 중간에 ElastiCache는 신청 단계에서 SNS + SQS와 아직 무엇을 써야할지 결정된게 없어서 넣었습니다. 여기에서는 데이터베이스 4개로 구성되어 있으며 ERD diagram 하고 reference 할 수 있습니다. 입소대기신청시스템 데이터베이스는 User_ID + Child_ID 로 구성되어 있고, 어린이집관리시스템은 어린이집 대기 / 등록 데이터베이스로 구성 되어있으며 어린이 집에 등록한 아동 정보 / 데이터베이스는 아동관리시스템에 저아됩니다.
아키텍처에서 왜 EKS (Kubernetes) ECS (Docker) 따로 사용한 이유?
티켓은 트래픽이 많아서 하단 이유로 사용
쿠버네티스(Kubernetes)와 도커(Docker)는 컨테이너화 분야에서 널리 사용되지만, 각각의 목적과 범위가 다릅니다. 쿠버네티스와 도커의 주요한 차이점은 다음과 같습니다:
기능:
도커: 도커는 개발자가 애플리케이션을 컨테이너로 빌드, 패키지화, 배포할 수 있게 해주는 플랫폼입니다. 단일 호스트 머신에서 컨테이너를 생성, 실행 및 관리하기 위한 도구와 기능을 제공합니다.
쿠버네티스: 쿠버네티스는 오픈 소스 컨테이너 오케스트레이션 플랫폼입니다. 컨테이너화된 애플리케이션을 여러 대의 머신 또는 노드 클러스터에서 자동으로 배포, 확장 및 관리합니다. 쿠버네티스는 컨테이너 스케줄링, 로드 밸런싱, 스케일링, 자가 치유 등의 기능을 제공합니다.
범위:
도커: 도커는 컨테이너화 프로세스 자체에 초점을 맞추고 있으며, 컨테이너 이미지 생성, 실행, 라이프사이클 관리를 단일 호스트에서 수행합니다.
쿠버네티스: 쿠버네티스는 여러 대의 머신에서 컨테이너화된 애플리케이션을 관리하는 데 중점을 둡니다. 컨테이너의 오케스트레이션을 처리하여 컨테이너가 효율적으로 실행, 확장 및 통신되도록 합니다.
컨테이너 관리:
도커: 도커는 가벼운 실행 환경인 도커 엔진을 제공하여 단일 머신에서 컨테이너를 빌드, 실행 및 관리할 수 있게 합니다. 이미지, 컨테이너, 볼륨, 네트워크 관리를 위한 도구를 포함하고 있습니다.
쿠버네티스: 쿠버네티스는 컨테이너를 더 높은 수준에서 관리하며, 하부 인프라를 추상화합니다. 컨테이너 배포 및 스케일링 자동화, 컨테이너 상태 모니터링, 컨테이너 네트워킹, 저장소 관리 등을 처리합니다.
확장성과 고가용성:
도커: 도커 스웜(Docker Swarm)은 일부 확장성과 고가용성을 달성하기 위해 사용될 수 있습니다. 하지만 고급 스케일링 및 장애 허용 기능 면에서는 쿠버네티스만큼 강력하거나 다양한 기능을 제공하지는 않습니다.
쿠버네티스: 쿠버네티스는 여러 대의 머신에서 컨테이너화된 애플리케이션을 효과적으로 관리하고 확장할 수 있도록 합니다. 자동 스케일링, 로드 밸런싱, 롤링 업데이트, 자가 치유 기능 등을 지원하여 고가용성과 장애 허용성을 보장합니다.
커뮤니티와 생태계:
도커: 도커는 큰 규모의 활발한 커뮤니티와 도커 허브(Docker Hub) 레지스트리에 다양한 컨테이너 이미지가 있습니다. 로컬 개발 및 작은 규모의 배포에 적합합니다.
쿠버네티스: 쿠버네티스는 강력한 커뮤니티와 그 주위에 구축된 다양한 도구와 서비스 생태계를 가지고 있습니다. 대규모 컨테이너 배포 관리에 널리 사용되며, 유연성과 확장성으로 알려져 있습니다.
요약하자면, 도커는 단일 호스트에서 컨테이너를 빌드하고 실행하는 데 초점을 맞춘 반면, 쿠버네티스는 클러스터 내에서 컨테이너화된 애플리케이션을 관리하고 오케스트레이션하는 포괄적인 플랫폼입니다. 도커는 독립적으로 사용될 수 있지만, 쿠버네티스는 대규모 컨테이너 배포를 관리하고 고급 기능을 제공하기 위해 설계되었습니다.
'Final Project' 카테고리의 다른 글
| Devops Day 72 (6.17) Final Project_Day 6 (토요일) (2) | 2023.06.18 |
|---|---|
| Devops Day 71 (6.16) Final Project_Day 5 (0) | 2023.06.18 |
| Devops Day 70 (6.15) Final Project_Day 4 (0) | 2023.06.16 |
| Devops Day 68 (6.13) Final Project_Day 2 (1) | 2023.06.14 |
| Devops Day 67 (6.12) Final Project_Day 1 (0) | 2023.06.12 |



