서비스 수준 관련 용어
서비스를 운영하는 데 있어서, 사용자에게 필요한 적정 수준을 정의하고 제공하기 위해, 서비스 제공자와 사용자는 서로 서비스 수준 협약(Service Level Agreements, SLA)을 맺습니다. 하지만 고객과의 약속이라는 것은 "어느 정도의 서비스를 제공해야 제대로 제공했다고 말할 수 있는 것인지"를 정확하게 명시하지 않으면 안 됩니다. 따라서, SRE 엔지니어는 척도를 통한 목표를 이해하고, 실제로 목표를 세우는 방법을 알아야 합니다. 여기서는 서비스 수준 관련 용어에 대해서 학습합니다.
SLI (서비스 수준 척도, Service Level Indicator)
서비스 수준 지표(SLI)는 기업이 고객에 대한 서비스 수준을 측정하는 데 도움이 되는 구체적인 지표입니다. SLI는 서비스 수준 목표(SLO)의 하위 섹션으로서, 전반적인 서비스 신뢰성에 영향을 미치는 서비스 수준 계약(SLA)의 일부입니다.
SLI는 일반적으로 백분율로 측정되며, 0%는 최악의 성능을 나타내고 100%는 완벽한 성능을 나타냅니다.
SLI는 실제로 어떻게 작동하나요?
기업은 SLI를 정확하게 추적하고 측정하는 데에는 시간과 자원이 필요하며, 경우에 따라서는 더 적게 측정하는 것이 더 나을 수도 있습니다. 가능한 모든 SLI를 측정하는 대신, 조직은 자신의 요구와 목표에 가장 관련성이 높은 몇 가지 SLI에 집중해야 합니다.
- 사용자를 대상으로 하는 시스템과 앱은 일반적으로 가용성, 처리량 및 지연 시간에 가장 관심이 있습니다. 이는 서비스 요청의 속도와 효과에 관한 것입니다.
- 저장 시스템은 내구성, 가용성 및 지연 시간을 강조합니다. 저장 시스템은 데이터의 액세스 및 저장 방식에 가장 관심이 있습니다.
- 빅 데이터 시스템은 처리량과 종단 간 지연 시간을 살펴봅니다. 데이터 시스템은 데이터 처리 파이프라인의 시작부터 끝까지 데이터가 처리되고 저장되는 데 얼마나 오래 걸리는지를 측정합니다.
- 정확성은 모든 시스템, SLI 및 SLO에 관련이 있습니다. 정확성은 고객에게 올바른 답변을 제공하거나 올바른 데이터를 검색하거나 올바른 분석을 제공하는 데 얼마나 정확했는지와 관련이 있습니다.
SLI를 추적하고 수집하는 방법
SLI를 정확하게 수집하고 추적하기 위해 기업은 사용자에게 영향을 미치는 다양한 문제를 놓치지 않기 위해 서버 측이 아닌 클라이언트 측에서 동작을 측정해야 합니다.
다음과 같은 방법으로 측정을 단순화하여 오류를 피할 수 있습니다.
- 특정 요청에 소요되는 시간이 너무 다르기 때문에 평균을 생성하지 않습니다. 평균은 결과를 흐릴 수 있습니다.
- 주요 지표에는 백분위수를 사용하여 가장 정확한 분포와 해당하는 SLI 속성을 보장합니다.
- 1분과 같은 특정 기간에 대해 간격을 집계합니다.
- 30초마다 한 번의 측정이 이루어지는 빈도를 추적합니다.
서비스 수준을 판단할 수 있는 몇 가지를 정량적으로 측정한 값으로, 주요 SLI는 다음과 같습니다.
- 응답 속도: 요청에 대한 응답이 리턴되기까지의 시간
- 에러율: 전체 요청 수 대비
- 처리량(throughput): 초당 처리할 수 있는 요청 수
- 가용성: 서비스가 사용 가능한 상태로 존재하는 시간의 비율
- 내구성: 데이터 저장이 중요한 목적인 서비스의 경우 특히 중요
SLO (서비스 수준 목표, Service Level Objectives)
SLO를 통해 DevOps 및 사이트 신뢰성 엔지니어링(SRE) 팀은 서비스의 유지 및 SLA 준수 정도를 평가하고 평가하는 데 더욱 용이해집니다.
서비스 수준 목표(SLO)의 주요 구성 요소는 무엇인가요?
어떤 기술의 성공은 한 가지에 기반합니다: 긍정적이거나 수용 가능한 사용자 경험입니다.
뛰어난 디지털 고객 경험을 구축하기 위해서는 서비스의 성능을 구성하는 지표에 대한 이해가 필요합니다. 애플리케이션이나 소프트웨어는 본질적으로 사용자 또는 종종 수백만 명의 사용자에게 서비스를 제공합니다.
이것이 서비스 SLO의 역할입니다. SLO의 주요 구성 요소를 살펴보겠습니다.
- 의무를 가진 사람은 SLO를 전달하고 유지하기 위해 필요한 개체 또는 그룹을 의미합니다.
- 유효 기간은 SLO가 전달되어야 하는 기간을 나타냅니다. 그 이상으로 전달되는 것은 SLA 위반입니다.
- 표현은 SLO가 무엇이며 어떻게 충족되어야 하는지를 구체화하는 언어를 의미합니다.
- 서비스 품질(QoS)은 다양한 측정값(SLI)을 통해 구성되며, 이를 종합하여 일반적으로 백분위 형식의 수치적인 SLO 달성 값을 나타냅니다.
SLI에 의해 측정된 서비스 수준의 목푯 값, 또는 일정 범위의 값을 의미합니다. 즉 SLO는 다음과 같이 표현됩니다.
SLI ≤ 목표치
최소값 ≤ SLI ≤ 최댓값
SLA (서비스 수준 협약, Service Level Agreements)
서비스 수준 계약(SLA)은 서비스 제공자와 고객 또는 거래처 간에 맺은 법적 의무 또는 일련의 의무로, 가용성, 책임성 및 기타 주요 지표에 대한 특정 품질 보증을 보장합니다.
SLA의 유형
고객과 서비스 제공자 모두 신뢰성, 품질 보증 및 최소한의 보장에 대한 공유된 이해를 만들기 위한 방법을 원합니다.
다양한 유형의 SLA는 고객 중심 SLA, 서비스 중심 SLA 및 기업 수준 SLA와 같은 다양한 수준의 계약을 정의합니다. SLA는 종종 SLA의 하위 부문인 서비스 수준 목표(SLO)로 정의됩니다.
SLA의 주요 구성 요소는 무엇인가요?
아래에서 SLA의 일부 주요 구성 요소를 살펴보겠습니다. 모든 기업이 이러한 측면을 모두 활용하지는 않을 수 있다는 점을 기억하는 것이 중요합니다.
- 성능 수준과 신뢰성
SLA에는 제품, 고객 요청 또는 서비스 내에서의 응답 능력과 성능 수준을 나타내는 신뢰성 있는 서비스 계약을 수립하는 조건이 포함됩니다.
- 보고 및 서비스 수준
기업은 서비스 수준의 품질과 성능을 감시하고 모니터링하는 방법이 필요합니다. 보고 프로세스는 기업이 다양한 데이터와 통계를 수집해야 합니다.
- 서비스 문제
SLA의 서비스 문제 구성 요소는 문제가 보고되어야 하는 단계와 순서를 정의합니다. 이에는 문제가 해결되어야 하는 시간대 및 문제와 관련된 응답 시간과 같은 수치적으로 정의 가능한 지표가 포함됩니다.
- 서비스 제공자의 결과
제공자가 약속을 이행하지 못할 때, SLA는 적절한 벌과 결과를 명시합니다.
SLA 최적화를 위한 메트릭 모범 사례
SLA는 종종 다양한 맥락에서 널리 사용되기 때문에 표준화하기가 어렵습니다.
"SLO를 달성하지 못하면 어떻게 되는지"를 적어놓은 약속입니다. SRE가 직접 관여하지는 않습니다.
SLA vs. SLO vs. SLI
SLA, SLO 및 SLI는 서비스 제공자와 고객 간의 계약 및 협약을 유지하기 위해 함께 작동합니다. 아래에서 각 용어를 살펴보고 고객-서비스 제공자 간의 관계에서 어떻게 작동하는지 알아보겠습니다. SLA, SLO 및 SLI는 중요한 메트릭의 속성, 해당 메트릭의 허용 범위를 설명하고 최종 사용자에게 전달합니다.
참고 : https://www.sumologic.com/glossary/sli-service-level-indicator/#:~:text=A%20service%20level%20indicator%20(SLI,that%20impact%20overall%20service%20reliability.
참고 : https://www.sumologic.com/glossary/slo-service-level-objective/
참고 : https://www.sumologic.com/glossary/sla-service-level-agreement/
참고 : https://www.techtarget.com/searchcustomerexperience/definition/service-level-indicator
What is service level indicator? | Definition from TechTarget
To properly measure customers' quality of service, you should use service level indicators. Learn what SLIs are and where they fit into SLAs.
www.techtarget.com
Service Level Agreement (SLA) - definition & overview | Sumo Logic
Explore what a Service Level Agreement is, the key components of SLAs, SLA metrics, and different types of SLAs. Learn how Sumo Logic's observability platform helps measure objectives and ensure you're meeting KPIs, deadlines, and long-term strategies.
www.sumologic.com
Service Level Objective (SLO) - definition & overview | Sumo Logic
Explore what a service-level object is, its key components, and how it compares to SLAs and SLIs. Learn how Sumo Logic helps measure objectives and ensure you're on track to meet KPIs, deadlines, and long-term strategies.
www.sumologic.com
Service Level Indicator (SLI) - definition & overview | Sumo Logic
Explore what a service level indicator is, common SLI metrics and terminology, how SLIs work in practice, and how to track and collect SLIs. Learn how Sumo Logic helps measure objectives and ensure you're on track to meet KPIs, deadlines, and long-term str
www.sumologic.com
지표 설정과 주요 목표 설정
지표 설정
서비스나 시스템에 있어 중요한 지표를 판단하는 근거가 있어야 합니다. 적절한 SLI의 선정은 시스템의 분류에 따라 달라질 수 있습니다.
- 사용자가 직접 대면하는 시스템
- 보통 프론트엔드에 해당하며, 이 경우 가용성, 응답 시간, 처리량이 중요합니다.
- 저장소 시스템
- 응답 시간, 가용성, 내구성이 중요합니다.
- 빅데이터 시스템
- 데이터 파이프라인이 이에 해당하며, 처리량, 그리고 엔드포인트 간 응답 시간이 중요합니다.
척도 수집
측정 원본을 합산하거나, 평균을 내거나 하는 방법이 있겠지만, 대부분의 경우 분포가 중요합니다. 일부 요청이 빠르게 처리되어도, 나머지 요청이 균일하게 느리다면 실제로 서비스는 느린 것으로 간주할 수 있습니다.
척도의 표준화
SLO를 설정할 때, 주요 SLI의 정의를 표준화시키면 편리합니다. 예를 들어 다음과 같습니다.
- 집계 간격: 1분
- 집계 범위: 하나의 클러스터에서 수행되는 모든 태스크
- 측정 빈도: 매 10분
- 집계에 포함할 요청: 전체 HTTP GET 요청
목표 설정하기
다음과 같은 목표를 설정할 수 있습니다. 다음은 성능에 중점을 둔 SLO입니다.
- GET 호출의 90%는 1ms 이내에 수행되어야 한다.
- GET 호출의 99%는 10ms 이내에 수행되어야 한다.
- GET 호출의 99.9%는 100ms 이내에 수행되어야 한다.
두 번째 발표
[C173] 모니터링 시스템에는 메트릭 수집을 위한 두 가지 방식의 메커니즘이 존재합니다. 바로 Pull 방식과 Push 방식입니다. 프로메테우스는 어떤 방식의 메커니즘을 사용하나요? 또한 Pull 방식과 Push 방식은 어떻게 다르며, 장단점은 무엇인지, 또한 해당 방식을 사용하는 모니터링 도구는 어떤 것들이 있는지 연구해 보세요.
내부 사용을 위한 모니터링 시스템 플랫폼 구축을 위해 오픈 소스 솔루션이나 상용 SaaS 제품을 사용할 수 있는 여러 가지 옵션이 있습니다.
데이터를 모니터링 플랫폼으로 전달하거나 모니터링 플랫폼이 데이터를 얻을 수 있는 방법을 고려해야 합니다. 이는 데이터 획득 방법의 선택을 포함합니다: Pull 또는 Push.
Pull 기반 모니터링 시스템은 이름에서 알 수 있듯이 지표를 적극적으로 얻는 모니터링 시스템으로, 모니터링이 필요한 대상은 원격으로 접근할 수 있는 기능을 갖추어야 합니다. Push 기반 모니터링 시스템은 데이터를 적극적으로 얻지 않고, 모니터링 대상은 지표를 적극적으로 푸시합니다.
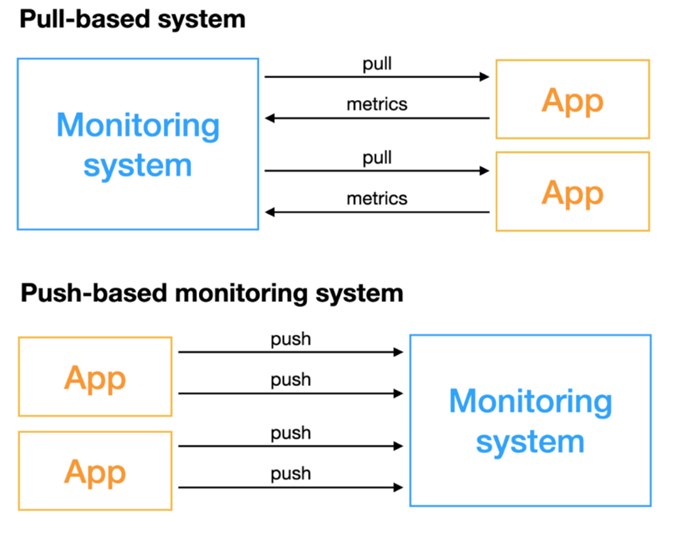
Pull 모델 아키텍처
데이터 획득의 핵심은 Pull 모듈로, 일반적으로 Prometheus와 같은 모니터링 백엔드와 함께 배포됩니다. 핵심 구성 요소는 다음과 같습니다:
1. 서비스 검색 시스템은 호스트 서비스 검색(일반적으로 회사의 CMDB 시스템에 의존), 응용 프로그램 서비스 검색(Consul 등) 및 PaaS 서비스 검색(Kubernetes 등)을 포함합니다. Pull 모듈은 이러한 서비스 검색 시스템에 연결할 수 있는 능력을 갖추어야 합니다.
2. 서비스 검색 부분 외에도, Pull 핵심 모듈은 일반적으로 일반 프로토콜을 사용하여 원격에서 데이터를 풀링합니다. 일반적으로 구성 풀링 간격, 타임아웃 간격, 지표 필터링, 이름 변경 및 간단한 프로세스 능력을 지원합니다.
3. 애플리케이션 엔드 SDK는 풀링이 가능하도록 고정 포트를 수신 대기하는 기능을 제공합니다.
4. 다양한 미들웨어 및 기타 시스템은 Pull 프로토콜과 호환되지 않기 때문에, 해당 시스템의 지표를 풀링하고 표준 Pull 인터페이스를 제공하기 위해 해당 시스템과 Exporter에 해당하는 Agent를 개발해야 합니다.
Push 모델 아키텍처
Push 모델은 간단하며, 다음과 같이 설명할 수 있습니다.
1. Push 에이전트는 다양한 모니터링 대상의 지표 데이터를 풀링하고 서버로 푸시하는 기능을 지원합니다. 모니터링 시스템과 결합된 방식으로 배포되거나 별도로 배포될 수 있습니다.
2. ConfigCenter(선택적)는 모니터링 대상, 수집 간격, 지표 필터링, 지표 처리 및 원격 대상과 같은 중앙 집중식 동적 구성 기능을 제공할 수 있습니다.
3. 애플리케이션 엔드 SDK는 데이터를 모니터링 백엔드 또는 로컬 에이전트로 전송하는 기능을 지원합니다(일반적으로 로컬 에이전트는 백엔드 인터페이스 세트도 구현합니다).
Pull 방식과 Push 방식의 장단점은 다음과 같습니다:
Pull 방식의 장점:
- 수집 주기를 클라이언트 측에서 제어할 수 있어 자유로운 설정이 가능합니다.
- 클라이언트가 필요한 메트릭만을 요청하여 효율적인 데이터 전송이 가능합니다.
- 서버에 과부하가 걸리더라도 클라이언트 측에서 별도로 제어가 가능합니다.
Pull 방식의 단점:
- 데이터 지연이 발생할 수 있습니다. 메트릭을 주기적으로 요청하기 때문에 실시간성이 필요한 경우에는 적합하지 않을 수 있습니다.
Push 방식의 장점:
- 실시간성이 요구되는 상황에 적합합니다. 메트릭 데이터를 즉시 수집할 수 있습니다.
- 메트릭을 생성하는 애플리케이션 또는 서비스 측에서 수집 로직을 구현하므로 클라이언트 측에서의 추가 작업이 필요하지 않습니다.
Push 방식의 단점:
- 수집 주기를 서버 측에서 제어해야 하므로 클라이언트 측에서의 설정이 제한적입니다.
- 서버에 과부하가 걸리는 경우 클라이언트 측에서 별도로 제어할 수 없습니다.
Pull or Push: How to Select Monitoring Systems?
This article introduces the Pull or Push selection in the monitoring system, comparing the two on the basis of various aspects encountered during actual customer scenarios.
www.alibabacloud.com
[C174] 어떤 조직의 SLO가 다음과 같습니다. "GET 호출의 99%는 10ms 이내에 수행되어야 한다" 그렇다면, 이러한 SLO를 달성하려면 어떤 메트릭을 수집하고 어떻게 계산해야 할까요? (척도는 표준화된 범용 지표를 사용합니다)
SLO를 통해 DevOps 및 사이트 신뢰성 엔지니어링(SRE) 팀은 서비스의 유지 및 SLA 준수 정도를 평가하고 평가하는 데 더욱 용이해집니다.
서비스 수준 목표(SLO)의 주요 구성 요소는 무엇인가요?
어떤 기술의 성공은 한 가지에 기반합니다: 긍정적이거나 수용 가능한 사용자 경험입니다.
뛰어난 디지털 고객 경험을 구축하기 위해서는 서비스의 성능을 구성하는 지표에 대한 이해가 필요합니다. 애플리케이션이나 소프트웨어는 본질적으로 사용자 또는 종종 수백만 명의 사용자에게 서비스를 제공합니다.
해당 SLO를 달성하기 위해 측정하고 계산해야 할 메트릭은 다음과 같습니다:
1. 호출 응답 시간 (Response Time): 모든 GET 호출에 대한 응답 시간을 측정합니다. 이는 각 호출의 시작부터 응답을 받는 데까지 걸리는 시간입니다.
2. 백분위 수 (Percentiles): 99%의 GET 호출이 10ms 이내에 수행되어야 하므로, 모든 호출의 응답 시간을 기록하고 99번째 백분위 수를 계산합니다. 이는 상위 99%의 호출이 소요하는 시간을 나타냅니다.
3. 지연 허용 값 (Allowed Latency): SLO에서 명시된 10ms를 기준으로합니다. 이 값은 GET 호출의 응답 시간이 이 값 이하로 유지되어야 한다는 의미입니다.
계산 방법은 다음과 같습니다:
1. 모든 GET 호출의 응답 시간을 측정하여 기록합니다.
2. 기록된 응답 시간을 사용하여 99번째 백분위 수를 계산합니다.
3. 계산된 99번째 백분위 수와 지연 허용 값(10ms)을 비교합니다.
4. 만약 99번째 백분위 수가 지연 허용 값 이하이면, SLO를 달성한 것으로 간주합니다.
이러한 방식으로 메트릭을 수집하고 계산하여 SLO를 달성할 수 있습니다.
'서비스 머니터링' 카테고리의 다른 글
| Devops Day 62 (6.2) 서비스 모니터링_Prometheus + Grafana (0) | 2023.06.04 |
|---|---|
| Devops Day 62 (6.2) 서비스 모니터링_쿠버네티스 클러스터 모니터링 (0) | 2023.06.03 |
| Devops Day 61 (6.1) 서비스 모니터링_Sprint Auto Scaling + CloudWatch를 이용한 알림 (0) | 2023.06.01 |
| Devops Day 60 (5.31) 서비스 모니터링_모니터링의 목표와 측정 항목 (0) | 2023.06.01 |


